Making StackStorm Fast
In this post I will describe changes to the StackStorm database abstraction layer which landed in StackStorm v3.5.0. Those changes will substantially speed up action executions and workflow runs for most users.
Based on the benchmarks and load testing we have performed, most actions which return large results and workflows which pass large datasets around should see speed ups in the range of up to 5-15x.
If you want to learn more about the details you can do that below. Alternatively if you only care about the numbers, you can go directly to the Numbers, numbers, numbers section.
Background and History
Today StackStorm is used for solving a very diverse set of problems – from IT and infrastructure provisioning to complex CI/CD pipeline, automated remediation, various data processing pipelines and more.
Solving a lot of those problems requires passing large datasets around – this usually involves passing around large dictionary objects to the actions (which can be in the range of many MBs) and then inside the workflow, filtering down the result object and passing it to other tasks in the workflow.
This works fine when working with small objects, but it starts to break when larger datasets are passed around (dictionaries over 500 KB).
In fact, passing large results around has been StackStorm’s achilles heel for many years now (see some of the existing issues - #3718, #4798, #625). Things will still work, but executions and workflows which handle large datasets will get progressively slower and waste progressively more CPU cycles and no one likes slow software and wasting CPU cycles (looking at you bitcoin).
One of the more popular workarounds usually involves storage those larger results / datasets in a 3d party system (such as a database) and then querying this system and retrieving data inside the action.
There have been many attempts to improve that in the past (see #4837, #4838, #4846) and we did make some smaller incremental improvements over the years, but most of them were in the range of a couple of 10% of an improvement maximum.
After an almost year long break from StackStorm due to the busy work and life situation, I used StackStorm again to scratch my own itch. I noticed the age old “large results” problem hasn’t been solved yet so I decided to take a look at the issue again and try to make more progress on the PR I originally started more than a year ago (https://github.com/StackStorm/st2/pull/4846).
It took many late nights, but I was finally able to make good progress on it. This should bring substantial speed ups and improvements to all StackStorm users.
Why the problem exists today
Before we look into the implemented solution, I want to briefly explain why StackStorm today is slow and inefficient when working with large datasets.
Primary reason why StackStorm is slow when working with large datasets is
because we utilize EscapedDictField() and EscapedDynamicField()
mongoengine field types for storing execution results and workflow state.
Those field types seemed like good candidates when we started almost 7 years ago (and they do work relatively OK for smaller results and other metadata like fields), but over the years after people started to push more data through it, it turned out they are very slow and inefficient for storing and retrieving large datasets.
The slowness boils down to two main reasons:
- Field keys need to be escaped. Since
.and$are special characters in MongoDB used for querying, they need to be escaped recursively in all the keys of a dictionary which is to be stored in the database. This can get slow with large and deeply nested dictionaries. - mongoengine ORM library we use to interact with MongoDB is known to be be very slow compared to using pymongo directly when working with large documents (see #1230 and https://stackoverflow.com/questions/35257305/mongoengine-is-very-slow-on-large-documents-compared-to-native-pymongo-usage). This is mostly due to the complex and slow conversion of types mongoengine performs when storing and retrieving documents.
Those fields are also bad candidates for what we are using them for. Data we are storing (results) is a more or less opaque binary blob to the database, but we are storing it in a very rich field type which supports querying on field keys and values. We don’t rely on any of that functionality and as you know, nothing comes for free – querying on dictionary field values requires more complex data structures internally in MongoDB and in some cases also indexes. That’s wasteful and unnecessary in our case.
Solving the Problem
Over the years there have been many discussions on how to improve that. A lot of users said we should switch away from MongoDB.
To begin with, I need to start and say I’m not a big fan of MongoDB, but the actual database layer itself is not the problem here.
If switching to a different database technology was justified (aka the bottleneck was the database itself and nor our code or libraries we depend on), then I may say go for it, but the reality is that even then, such a rewrite is not even close to being realistic.
We do have abstractions / ORM in place for working with the database layer, but as anyone who was worked in a software project which has grown organically over time knows, those abstractions get broken, misused or worked around over time (for good or bad reasons, that’s it’s not even important for this discussion).
Reality is that moving to a different database technology would likely require many man months hours of work and we simply don’t have that. The change would also be much more risky, very disruptive and likely result in many regressions and bugs – I have participated in multiple major rewrites in the past and no matter how many tests you have, how good are the coding practices, the team, etc. there will always be bugs and regressions. Nothing beats miles on the code and with a rewrite you are removing all those miles and battle tested / hardened code with new code which doesn’t have any of that.
Luckily after a bunch of research and prototyping I was able to come up with a relatively simple solution which is much less invasive, fully backward compatible and brings some serious improvements all across the board.
Implemented Approach
Now that we know that using DictField and DynamicField is slow and
expensive, the challenge is to find a different field type which offers
much better performance.
After prototyping and benchmarking various approaches, I was able to find that using binary data field type is the most efficient solution for our problem – when using that field type, we can avoid all the escaping and most importantly, very slow type conversions inside mongoengine.
This also works very well for us, since execution results, workflow results, etc. are just an opaque blob to the database layer (we don’t perform any direct queries on the result values or similar).
That’s all good, but in reality in StackStorm results are JSON dictionaries which can contain all the simple types (dicts, lists, numbers, strings, booleans - and as I recently learned, apparently even sets even though that’s not a official JSON type, but mongoengine and some JSON libraries just “silently” serialize it to a list). This means we still need to serialize data in some fashion which can be deserialized fast and efficiently on retrieval from the database.
Based on micro benchmark results, I decided to settle down on JSON, specifically orjson library which offers very good performance on large datasets. So with the new field type changes, execution result and various other fields are now serialized as JSON string and stored in a database as a binary blob (well, we did add some sugar coat on top of JSON, just to make it a bit more future proof and allow us to change the format in future, if needed and also implement things such as per field compression, etc.).
Technically using some kind of binary format (think Protobuf, msgpack, flatbuffers, etc.) may be even faster, but those formats are primarily meant for structured data (think all the fields and types are known up front) and that’s not the case with our result and other fields – they can contain arbitrary JSON dictionaries. While you can design a Protobuf structure which would support our schemaless format, that would add a lot of overhead and very likely in the end be slower than using JSON + orjson.
So even though the change sounds and looks really simple (remember – simple code and designs are always better!) in reality it took a lot of time to get everything to work and tests to pass (there were a lot of edge cases, code breaking abstractions, etc.), but luckily all of that is behind us now.
This new field type is now used for various models (execution, live action, workflow, task execution, trigger instance, etc.).
Most improvements should be seen in the action runner and workflow engine service layer, but secondary improvements should also be seen in st2api (when retrieving and listing execution results, etc.) and rules engine (when evaluating rules against trigger instances with large payloads).
Numbers, numbers, numbers
Now that we know how the new changes and field type works, let’s look at the most important thing – actual numbers.
Micro-benchmarks
I believe all decisions like that should be made and backed up with data so I started with some micro benchmarks for my proposed changes.
Those micro benchmarks measure how long it takes to insert and read a document with a single large field from MongoDB comparing old and the new field type.
We also have micro benchmarks which cover more scenarios (think small values, document with a lot of fields, document with single large field, etc.), but those are not referenced here.
1. Database writes
 This screenshot shows that the new field type (json dict field) is
~10x faster over EscapedDynamicField and ~15x over EscapedDictField when saving 4 MB field
value in the database.
This screenshot shows that the new field type (json dict field) is
~10x faster over EscapedDynamicField and ~15x over EscapedDictField when saving 4 MB field
value in the database.
2. Database reads
 This screenshot shows that the new field is about ~7x faster
over EscapedDynamicField and ~40x over EscapedDictField..
This screenshot shows that the new field is about ~7x faster
over EscapedDynamicField and ~40x over EscapedDictField..
P.S. You should only look at the relative change and not absolute numbers. Those benchmarks ran on a relatively powerful server. On a smaller VMs you may see different absolute numbers, but the relative change should be about the same.
Those micro benchmarks also run daily as part of our CI to prevent regressions and similar and you can view the complete results here.
End to end load tests
Micro benchmarks always serve as a good starting point, but in the end we care about the complete picture.
Things never run in isolation, so we need to put all the pieces together and measure how it performs in real-life scenarios.
To measure this, I utilized some synthetic and some more real-life like actions and workflows.
1. Python runner action
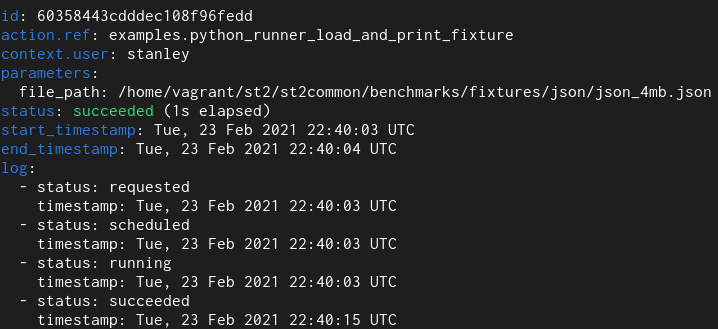
Here we have a simple Python runner action which reads a 4 MB JSON file from disk and returns it as an execution result.
Old field type
New field type
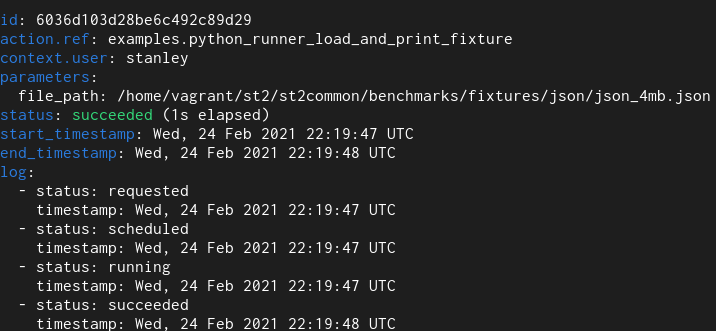
With the old field type it takes 12 seconds and with the new one it takes 1.
For the actual duration, please refer to the “log” field. Previous versions of StackStorm contained a bug and didn’t accurately measure / reprt action run time – the end_timestamp – start_timestamp only measures how long it took for action execution to complete, but it didn’t include actual time it took to persist execution result in the database (and with large results actual persistence could easily take many 10s of seconds) – and execution is not actually completed until data is persisted in the database.
2. Orquesta Workflow
In this test I utilized an orquesta workflow which runs Python runner action which returns ~650 KB of data and this data is then passed to other tasks in the workflow.
Old field type
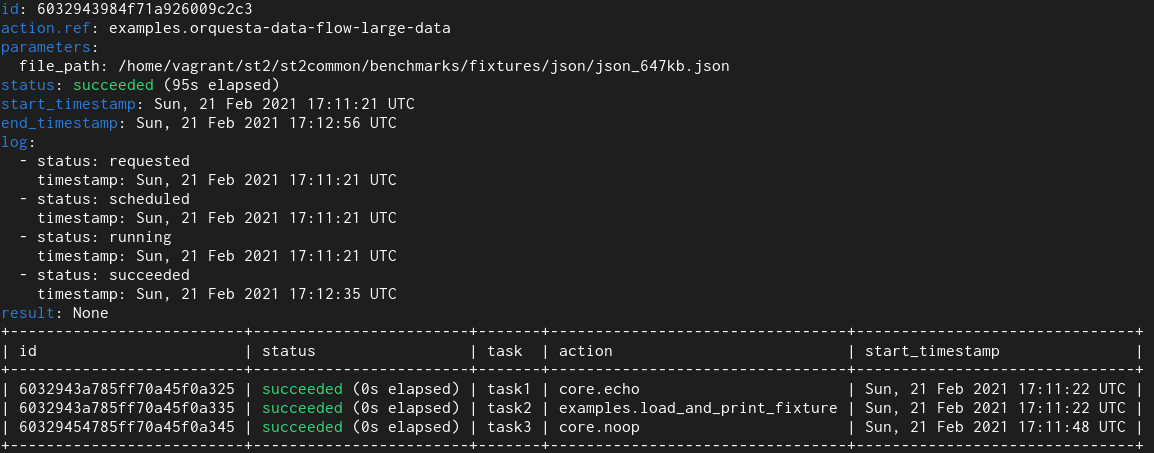
New field type
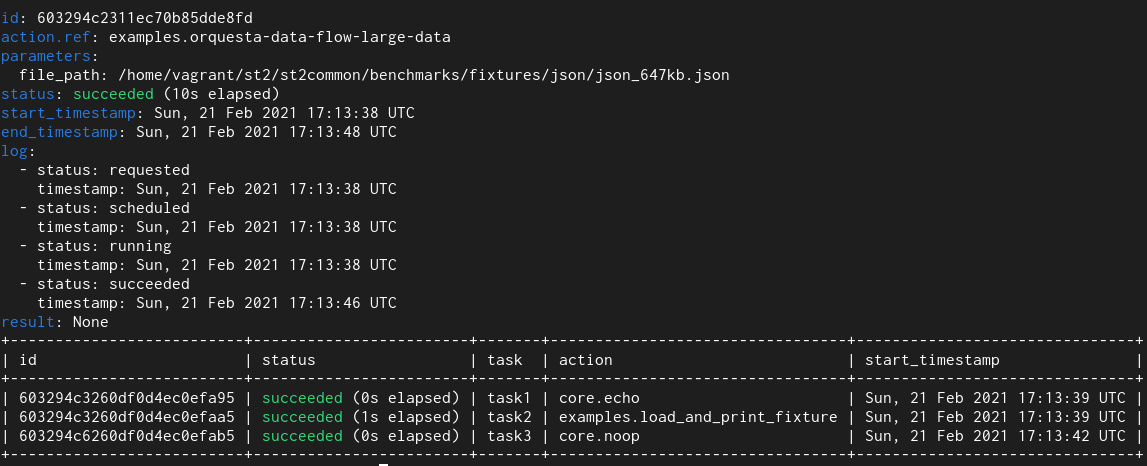
Here we see that with the old field type it takes 95 seconds and with the new one it takes 10 seconds.
With workflows we see even larger improvements. The reason for that is that actual workflow related models utilize multiple fields of this type and also perform many more database operations (read and writes) compared to simple non-workflow actions.
You don’t need to take my word for it. You can download StackStorm v3.5.0 and test the changes with your workloads.
Some of the early adopters have already tested those changes before StackStorm v3.5.0 was released with their workloads and so far the feedback has been very positive - speed up in the range of 5-15x.
Other Improvements
In addition to the database layer improvements which are the start of the v3.5.0 release, I also made various performance improvements in other parts of the system:
- Various API and CLI operations have been sped up by switching to orjson for serializarion and deserialization and various other optimizations.
- Pack registration has been improved by reducing the number of redundant queries and similar.
- Various code which utilizes
yaml.safe_loadhas been speed up by switching to C versions of those functions. - ISO8601 / RFC3339 date time strings parsing has been speed up by switching to
udatetimelibrary - Service start up time has been sped by utilizing
stevedorelibrary more efficiently. - WebUI has been substantially sped up - we won’t retrieve and display very large results by default anymore. In the past, WebUI would simply freeze the browser window / tab when viewing the history tab. Do keep in mind that righ now only the execution part has been optimized and in some other scenarios WebUI will still try to load syntax highlighting very large datasets which will result in browser freezing.
Conclusion
I’m personally very excited about those changes and hope you are as well.
They help address one of StackStorm’s long known pain points. And we are not just talking about 10% here and there, but up to 10-15x improvements for executions and workflows which work with larger datasets (> 500 KB).
That 10-15x speed up doesn’t just mean executions and workflows will complete faster, but also much lower CPU utilization and less wasted CPU cycles (as described above, due to the various conversions, storing large fields in the database and to a lesser extent also reading them, was previously a very CPU intensive task).
So in a sense, you can view of those changes as getting additional resources / servers for free – previously you might have needed to add new pods / servers running StackStorm services, but with those changes you should able to get much better throughput (executions / seconds) with the existing resources (you may even be able to scale down!). Hey, who doesn’t like free servers :)
This means many large StackStorm users will be able to save many hundreds and thousands of $ per month in infrastructure costs. If this change will benefit you and your can afford it, check Donate page on how you can help the project.
Thanks
I would like to thank everyone who has contributed to the performance improvements in any way.
Thank to everyone who has helped to review that massive PR with over 100 commits (Winson, Drew, Jacob, Amanda), @guzzijones and others who have tested the changes while they were still in development and more.
This also includes many of our long term uses such as Nick Maludy, @jdmeyer3 and others who have reported this issue a long time ago and worked around the limitations when working with larger datasets in various different ways.
Special thanks also to v3.5.0 release managers Amanda and Marcel.